目录
Mysql基础学习
1、索引的底层原理
Mysql索引的实现是B+树,主要从以下几个方面考虑:
- 查找次数
- 范围查询优化
- 磁盘IO次数
1、HASH
哈希表是做数据快速检索的有效工具,首先HASH算法,也叫散列算法,把任意值(key)通过哈希函数变换为固定长度的key地址,通过地址定位到具体数据。
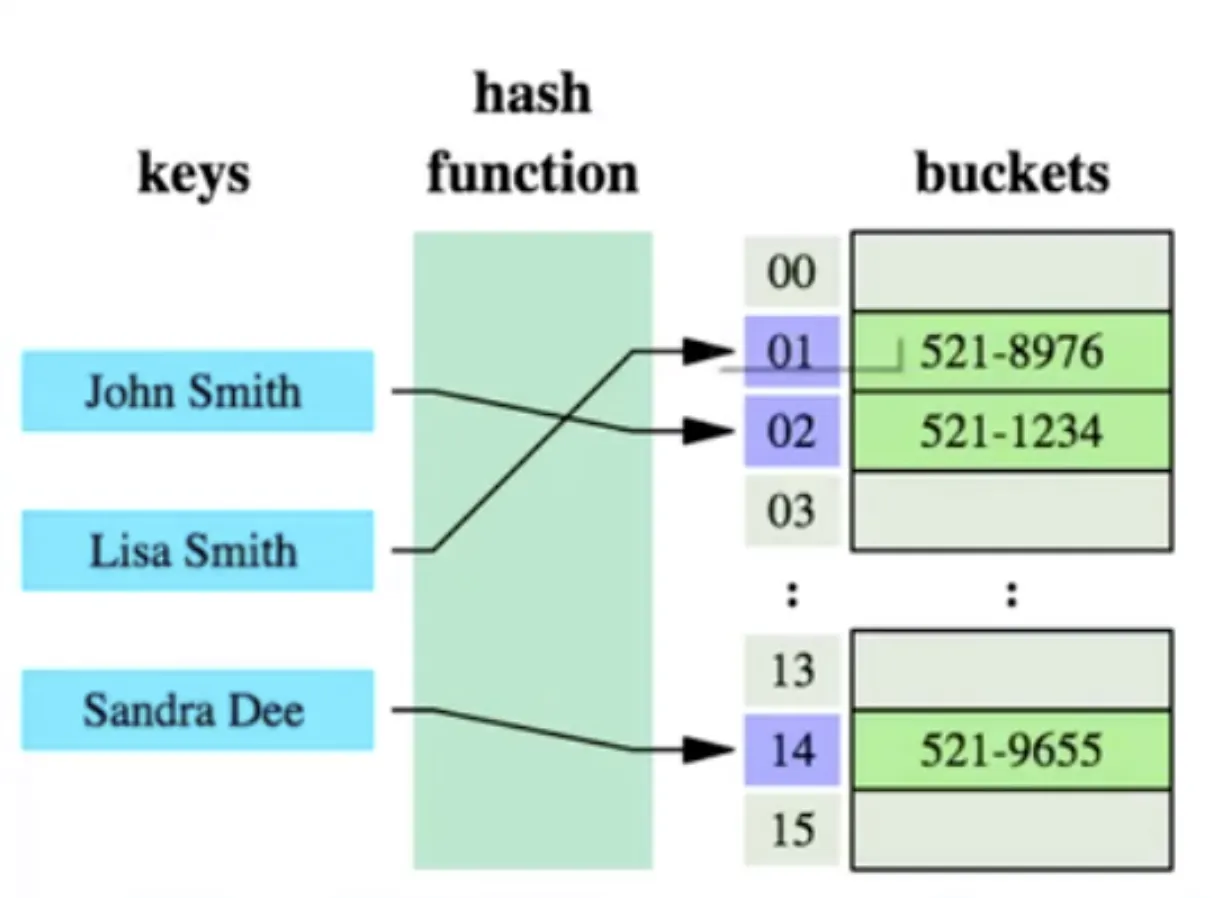
不考虑hash碰撞的话,时间复杂度为O(1)。遇到hash碰撞的话,按照生成一个链表的思路解决(hashmap的初期底层实现)。定位到key之后再遍历链表查找对应的key。
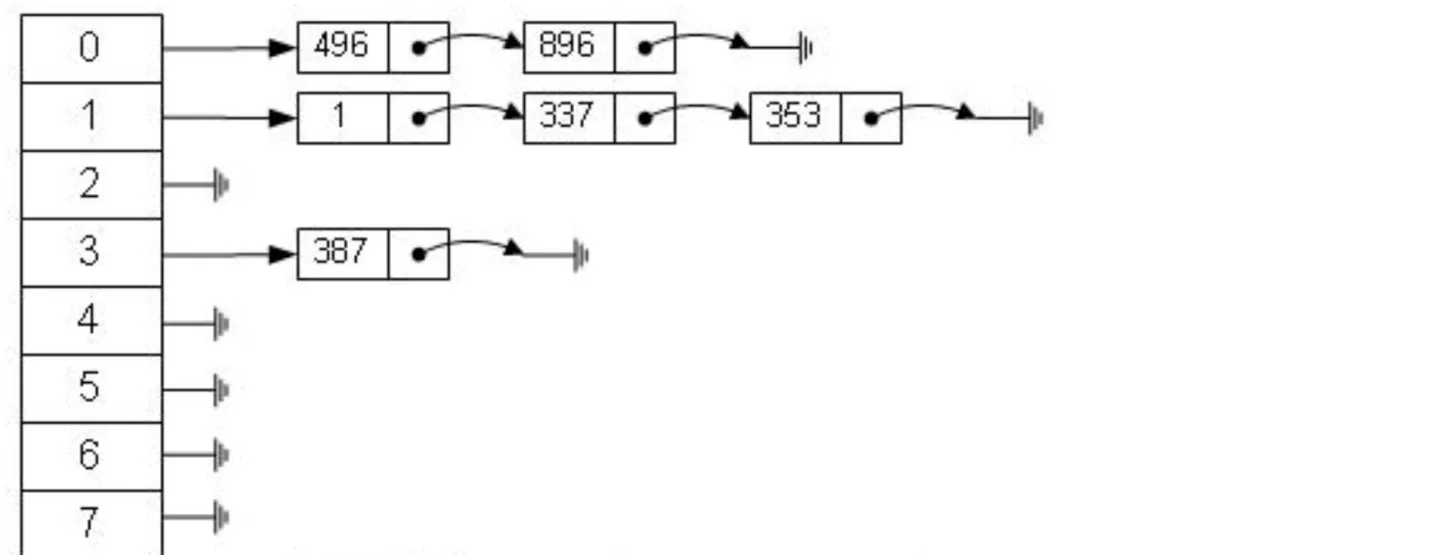
但是hash在针对范围查询时却束手无策,所以虽然可以快速检索到数据,也无法作为索引的底层数据结构实现
2、二叉查找树(BST)
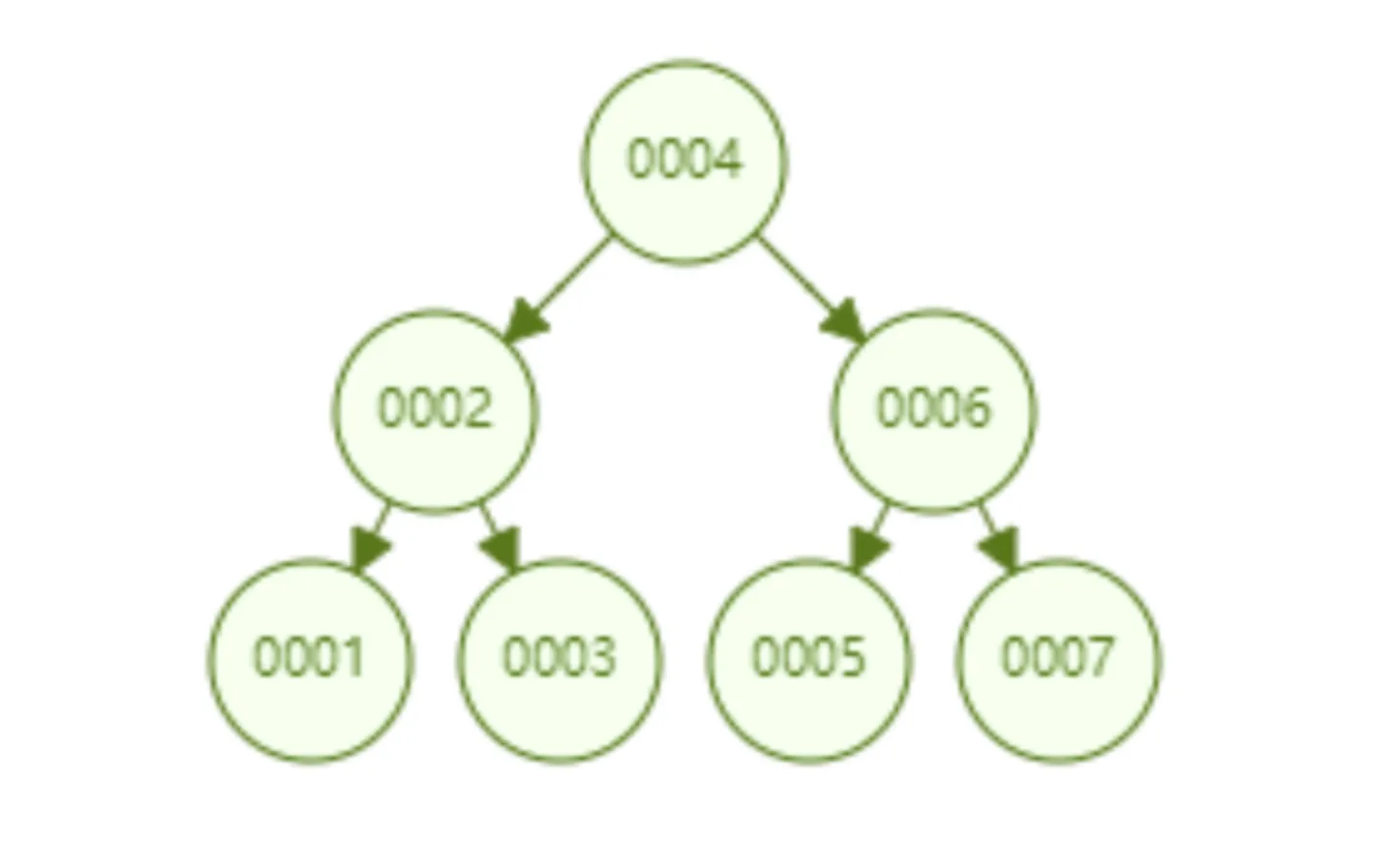
二叉查找树的时间复杂度为 O(lgn),比如我们查找数据为0007的节点,只需三次既可以查找到。在应对范围查询时,例如id>5的数据,我们只需要定位到0006,然后取其节点以及右子树即可,对于范围查询的性能也很强。
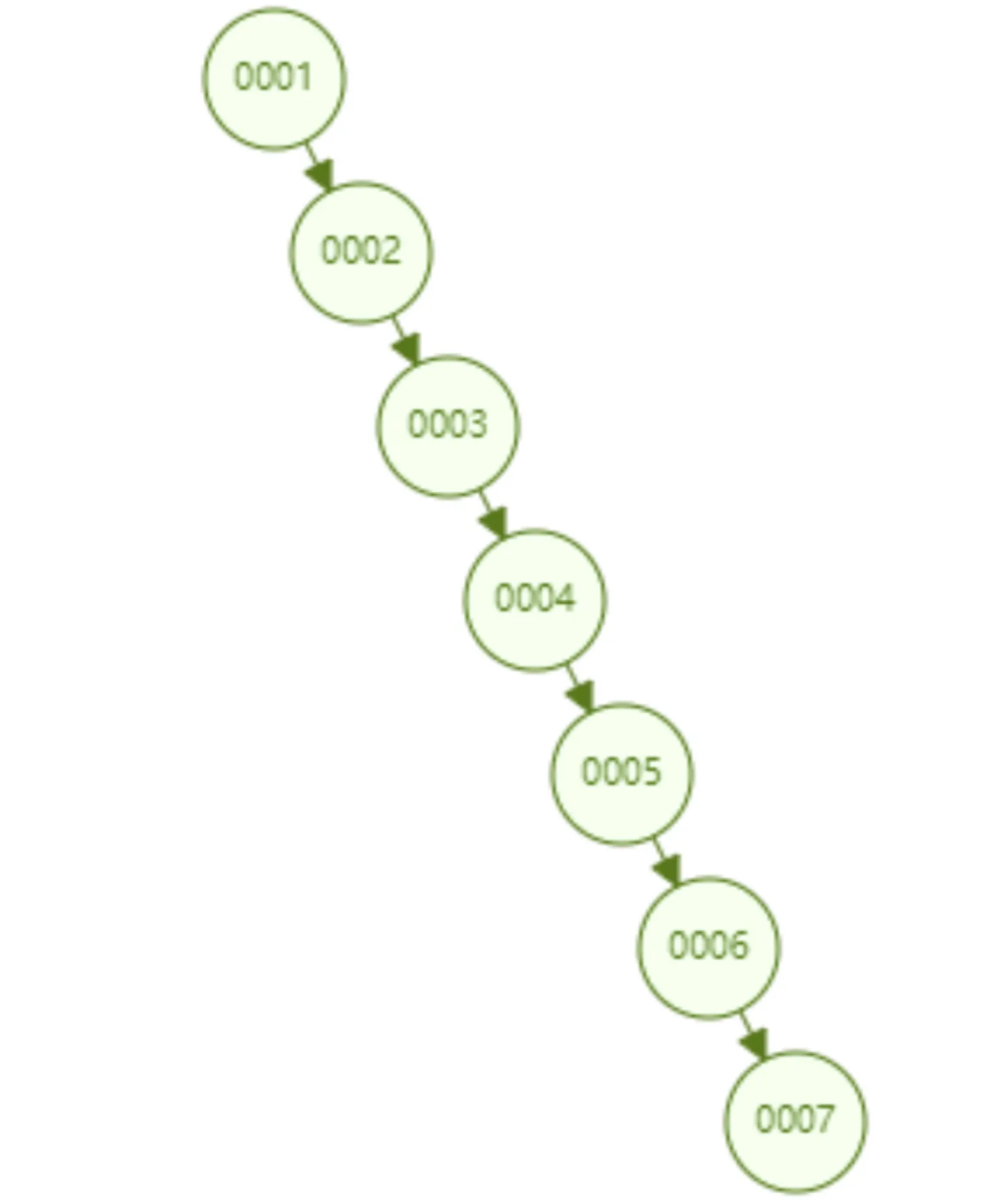
但是二叉树有个致命缺点:极端情况会退化成链表,如下。而在数据库中,自增的主键是个非常常见的形式,所以二叉树不适合作为索引的底层结构。
3、AVL树和红黑树
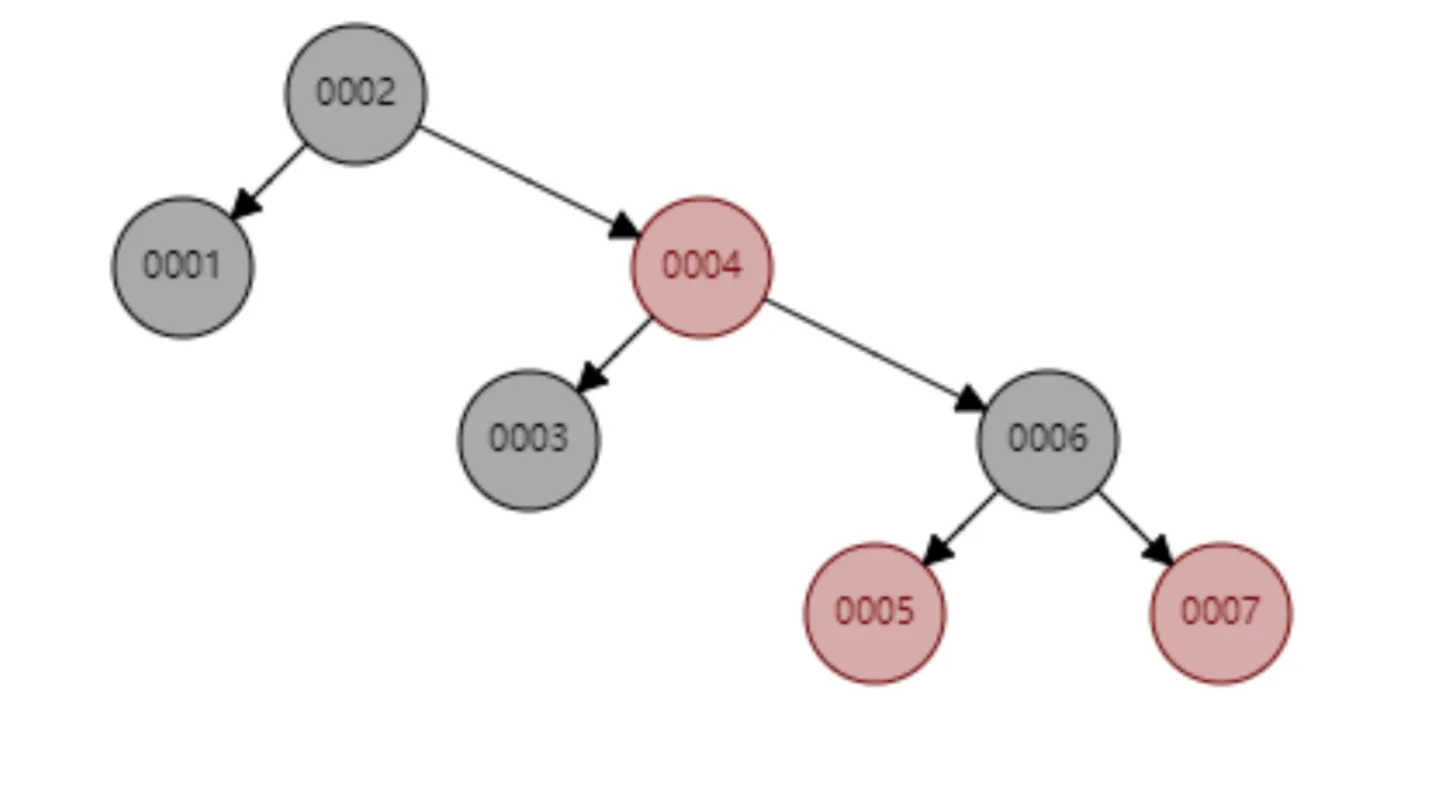
AVL树和红黑树都是自平衡树,可以通过自动旋转调整形态,始终保持基本平衡的状态。但是红黑树也有个问题,可能会一直右倾,如下,所以也没有完全处理退化为链表的情况。
AVL树是更严格的自平衡二叉树,基本解决退化为链表或者右倾的问题,它有不错的查找性能还可以实现范围查找和数据排序。但是需要考虑如下问题:
数据库查询数据的瓶颈在于磁盘 IO,如果使用的是 AVL 树,我们每一个树节点只存储了一个数据,我们一次磁盘 IO 只能取出来一个节点上的数据加载到内存里,那比如查询 id=7 这个数据我们就要进行磁盘 IO 三次,这是多么消耗时间的。所以我们设计数据库索引时需要首先考虑怎么尽可能减少磁盘 IO 的次数。
磁盘 IO 有个有个特点,就是从磁盘读取 1B 数据和 1KB 数据所消耗的时间是基本一样的,我们就可以根据这个思路,我们可以在一个树节点上尽可能多地存储数据,一次磁盘 IO 就多加载点数据到内存,这就是 B 树,B+树的的设计原理了。
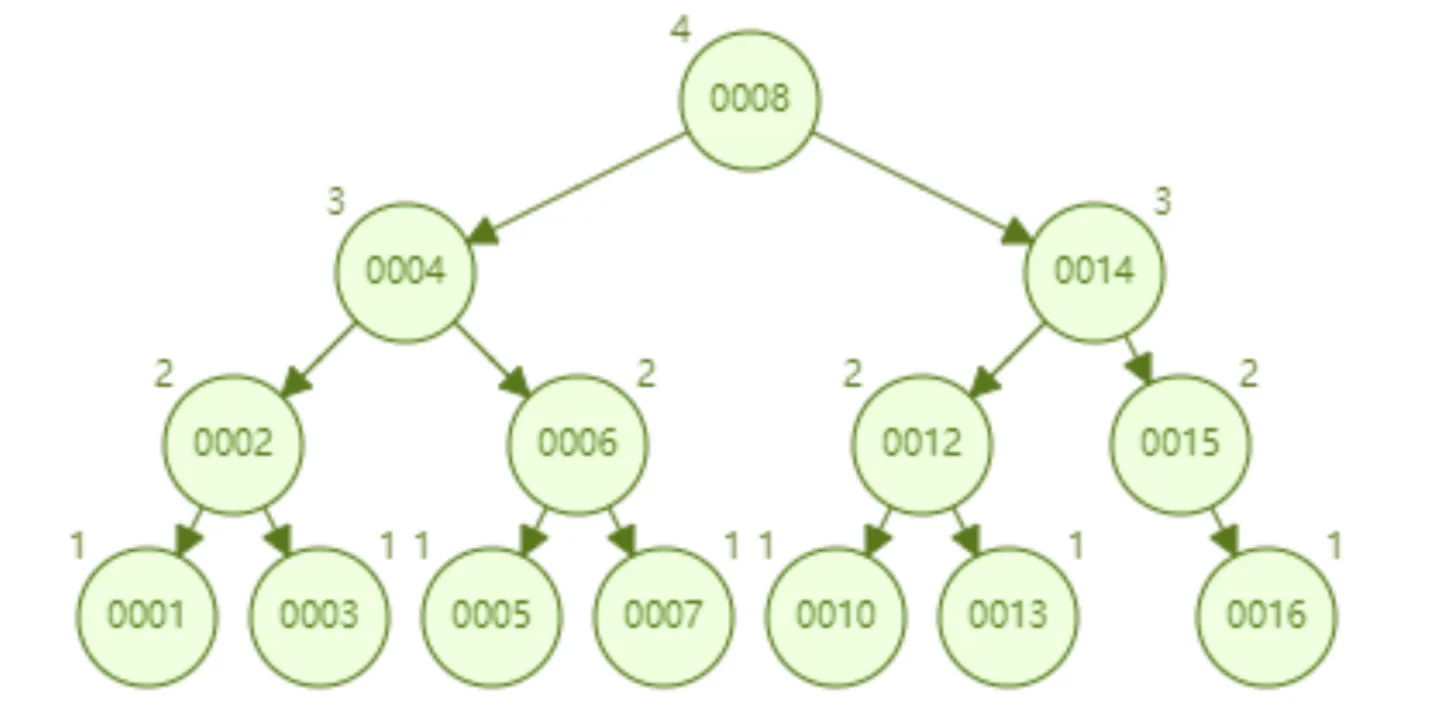
4、B树
下面这个 B 树,每个节点限制最多存储两个 key,一个节点如果超过两个 key 就会自动分裂。比如下面这个存储了 7 个数据 B 树,只需要查询两个节点就可以知道 id=7 这数据的具体位置,也就是两次磁盘 IO 就可以查询到指定数据,优于 AVL 树。
B树作为索引有如下优点:
- 优秀检索速度,时间复杂度:B 树的查找性能等于 O(h*logn),其中 h 为树高,n 为每个节点关键词的个数;
- 尽可能少的磁盘 IO,加快了检索速度;
- 可以支持范围查找。
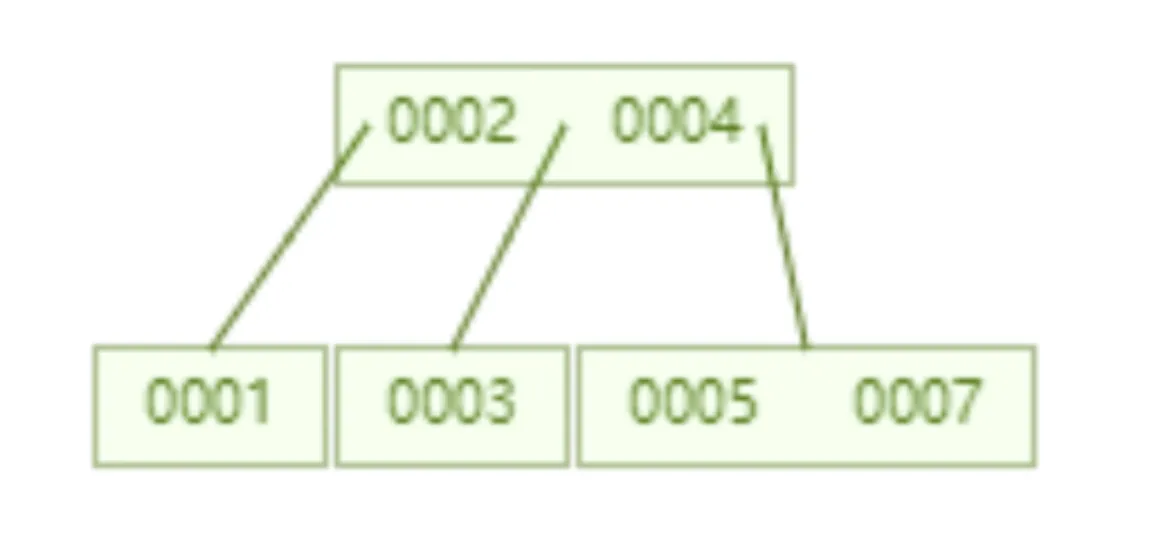
5、B+树
 B树和B+树的区别如下下:
B树和B+树的区别如下下:
- 树一个节点里存的是数据,而 B+树存储的是索引(地址),所以 B 树里一个节点存不了很多个数据,但是 B+树一个节点能存很多索引,B+树叶子节点存所有的数据
- B+树的叶子节点是数据阶段用了一个链表串联起来,便于范围查找。
通过 B 树和 B+树的对比我们看出,B+树节点存储的是索引,在单个节点存储容量有限的情况下,单节点也能存储大量索引,使得整个 B+树高度降低,减少了磁盘 IO。其次,B+树的叶子节点是真正数据存储的地方,叶子节点用了链表连接起来,这个链表本身就是有序的,在数据范围查找时,更具备效率。因此 Mysql 的索引用的就是 B+树,B+树在查找效率、范围查找中都有着非常不错的性能。
本文作者:刘涛
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!